Dokumentation: Regression mit FFNN
Allgemein
In dieser Aufgabe wird eine Regression an ein Polynom 4. Grades mit einen Neural Network durchgeführt.
Um das Modell zu trainieren wählt der Benutzer zunächst die gewünschten Einstellungen und Parameter und drückt dann den Knopf "Train" um den Vorgang zu starten.
Das Modell kann durch die entsprechenden Regler/Schaltflächen angepasst werden:
Epochs: Einstellung von den Epochs/Iterationen
Learning Rate: Einstellung der Learning Rate am Modell
Noise: Einstellung um die Trainingsdaten zu verrauschen
Samples: Anzahl der Trainingsdaten
Optimizer: Einstellung zwischen den Optimizer Adam und Stochastic Gradient Descent
Darüberhinaus gibt es weiterhin 3 Schaltflächen um diese Parameter Einzustellen auf Underfitting, Perfect Fit und Overfitting
Underfitting: Parameter werden angepasst um das Underfitting Phanömen zu veranschaulichen: Der Graph passt sich zu wenig den Trainingsdaten an.
Perfect-Fit: Parameter werden angepasst um ein optimales Ergebnis zu veranschaulichen: Der Graph passt sich den ursprünglichen Graph an.
Overfitting: Parameter werden angepasst um das Overfitting Phanömen zu veranschaulichen: Der Graph passt sich zu sehr den Trainingsdaten an.
Beschreibung Modell
Um die Regression zu veranschaulichen wird das Modell geplottet.
Der Graph passt sich sofort dynamisch den aktuell eingestellten Parametern an.
Der Modell erzeugt N-Trainingsdaten von -1 bis +1 und normiert diese.
Bei den geplotteten Graphen handelt es sich um die Funktion y(x) = (x+0.8)*(x-0.2)*(x-0.3)*(x-0.6) oder anders ausgedrückt x⁴ -0.3x³ -0.52x² + 0,252x - 0.00288.
Beim Starten des Modells mit der Taste "Train" wird zur Trainingszeit visualisiert, wie sich der rote Graph den Trainingsdaten anpasst (hellblaue Punkte), der anfangs initialisierte Graph ist mit zufälligen Koeffizienten a, b, c, d, e erzeugt und passt sich den Trainingsdaten über die Iterationen an.
Außerdem öffnet sich beim Starten zusätzlich ein Menü von rechts, in der Informationen über das Neuronale Netz und die Trainingsperformance des aktuellen Vorgangs dargestellt ist.
Unter dem Graphen befindet sich außerdem weitere Informationen, in der festgehalten wird, wie der tatsächliche Graph aussieht (Before), der Initialisierte Graph mit zufälligen Koeffizienten (Initialised), und wie der am Ende ermittelte Graph aussieht (Predicted).
Experimentieren mit den Modell Resultate
Folgender Abschnitt setzt sich mit dem Experimentieren an den erstellten Modell auseinander.
Fall 1: Underfitting

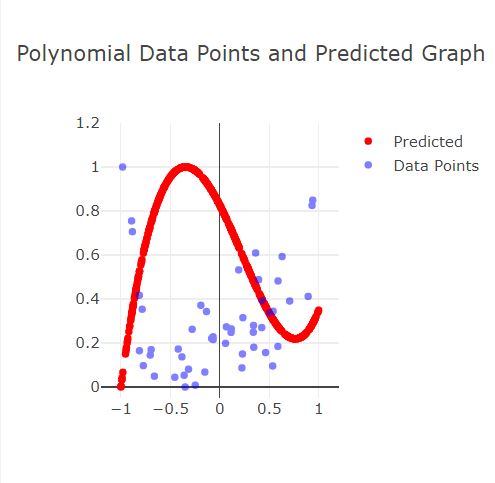
Wie in der oberen Abbildung zu sehen, passt sich die rote Linie zu wenig den Datenpunkten an.
Durch die zu wenig eingestellten Epochs (5) kann sich die rote Linie nicht den Trainingsdaten anpassen.
Auch passt sich der Graph zu langsam den Trainingsdaten an, wegen der zu niedrig eingestellten Learning Rate.
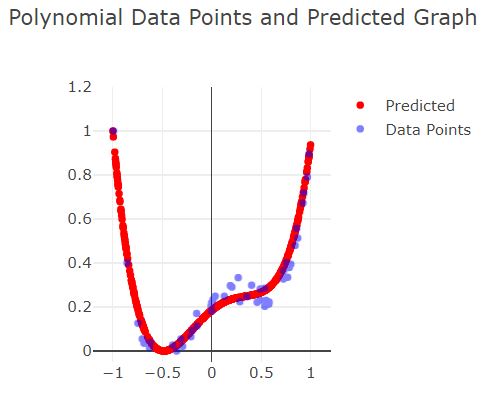
Fall 2: Overfitting

Die rote Linie passt sich bei diesen Beispiel zu sehr den Trainingsdaten an und nicht den tatsächlichen Graphen.
Durch die Einstellungen von zu viel Epochs (150) und einer hohen Learning Rate, passt sich der Graph zu sehr an die Trainingsdaten an und nicht an den eigentlichen Graphen.
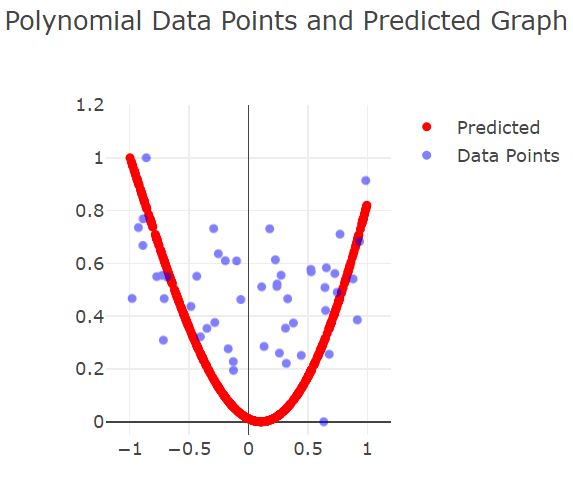
Fall3: Perfect Fit

Die rote Linie passt sich bei diesen Beispiel den tatsächlichen Graph nahezu an.
Durch die Einstellungen von zu nicht zu vielen und nicht zu wenigen Epochs(75) und einer geeigneten Learning Rate, mit nicht zu sehr verrauschten Daten passt sich der Graph den tatsächlichen Graphen an.
Fall 4: Zu wenige Trainingsdaten
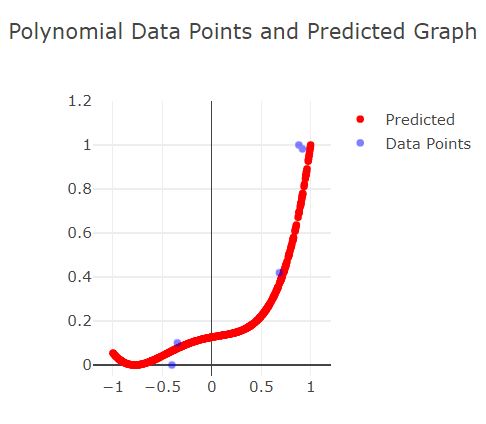
Durch zu wenige Trainingsdaten kann auch bei einer hohen Anzahl von Epochs, der tatsächliche Graph nicht erzeugt werden.
Weitere Anmerkungen
Werden die Trainingsdaten zu sehr verrauscht (Noise), kann auch hier der tatsächliche Graph nicht mehr ermittelt werden.
Aus den oberen Beispielen, kann somit geschlussfolgert werden, um ein richtiges Modell zu trainieren, ist es immens wichtig die richtigen Parameter einzustellen.
Höhere Epochs und Learning Rate führen bei zu hoher Einstellungen nicht zum Perfect Fit sondern meistens zu Overfitting.
Implementierung des Codes
Bei der Implementierung des Codes wurde das Tutorial von Tensorflow.js "Making Predicitions from 2D Data" genommen und der Code entsprechend angepasst.
Im Folgenden werden die relevantesten erstellten Codeauschnitte erläutert
Trainingsdaten erzeugen
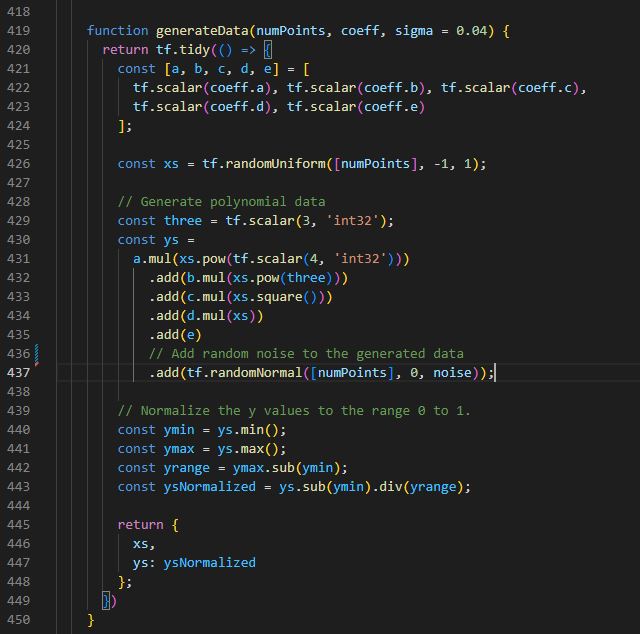
Die Methode generateData() erstellt aus einen Graphen die Trainingsdaten, normiert diese und legt sie in Tensoren ab.
Um diese Daten erzeugen zu können, nimmt die Methode die Werte a, b, c, d, e entgegen, die für die Koeffizieten eines Polynom 4. Grades stehen. (Zeile 420 - 423).
Durch in Zeile 426 tf.randomUniform() werden eine zufällige Anzahl (keine Normalverteilung) an X-Punkten zwischen -1 und 1 erzeugt.
Zeile 428 - 437 generiert nun das Polynom 4. Grades in der x4 + x3 + x2 + x + 1 Form und verrauscht diese Daten zusätzlich.
Zum Schluss werden die generierten Trainingsdaten noch normiert und diese Werte zurückgeliefert.
Graph initialisieren

Die rote Linie welche den ermittelten Graph darstellt und sich den tatsächlichen Graph anpassen soll wird zufällig erzeugt.
Die jeweiligen Koeffizienten a, b, c, d, e werden zufällig von -1 bis 1 erzeugt.
Durch diese zufällige Initialisierung gelingt somit immer ein anderes Szenario zu erzeugen, bei gleichbleibenden Parametern.
Model testen
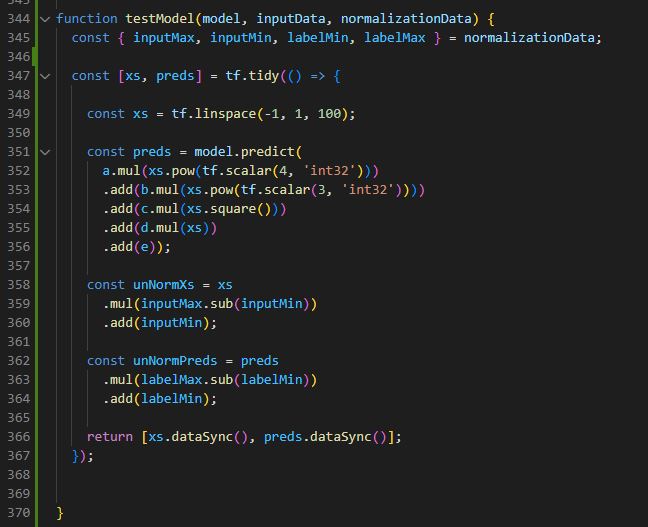
Die testModel() Methode, testet das Modell.
Die erzeugten Trainingsdaten von generateData() werden in diese Methode geliefert und weiterverarbeitet.
In Zeile 351 bis 356 wird durch die predict() Methode die generierten Trainingsdaten von tatsächlichen Modell mit dem zufällig generierten Polynom 4. Grades mit seinen Koeffizienten verglichen.
Nachdem dieser Prediction werden die Daten nun erneut normiert und zurückgegeben.
Verwendete Werkzeuge Quellen
Die Webseite läuft über einen Cloudflare-Webserver und nimmt sich die Daten aus einen erstellten GitHub Repository.
Die Erstellung erfolgt über CSS HTML Javascript und der Visual Studio Code IDE
Für die nächsten zukünftigen Einsendeaufgaben wurde außerdem, eine Navigationsleiste angelegt, diese funktionieren zum gegenwärtigen Zeitpunkt noch nicht und werden mit den nächsten ESAs verlinkt.
Frameworks und Bibliotheken
Layout - Gestaltung der Webseite: W3.CSS
Für den Graphen wurde die Plotly.js und die tfjs-vis Bibliothek verwendet.
Für die Erstellung des Neuronalen Netzes wurde die Tensorflow.js Bibliothek verwendet.
Stylesheets
Dokumentationen
Regression mit FFNN